Not bad by half.
Up until now we have dealt with whole numbers. Extending this to fractions is not too difficult as we are really just using the same mechanisms that we are already familiar with. Binary fractions introduce some interesting behaviours as we'll see below.
In this section, we'll start off by looking at how we represent fractions in binary. Then we will look at binary floating point which is a means of representing numbers which allows us to represent both very small fractions and very large integers. This is the default means that computers use to work with these types of numbers and is actually officially defined by the IEEE. It is known as IEEE 754.
Binary is a positional number system. It is also a base number system. For a refresher on this read our Introduction to number systems. As we move a position (or digit) to the left, the power we multiply the base (2 in binary) by increases by 1. As we move to the right we decrease by 1 (into negative numbers).
So in decimal the number 56.482 actually translates as:
| 5 * 101 | 50 |
| 6 * 100 | 6 |
| 4 * 10-1 | 4/10 |
| 8 * 10-2 | 8/100 |
| 2 * 10-3 | 2/1000 |
In binary it is the same process however we use powers of 2 instead.
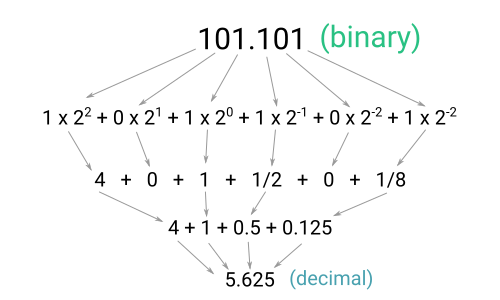
So in binary the number 101.101 translates as:
| 1 * 22 | 4 |
| 0 * 21 | 0 |
| 1 * 20 | 1 |
| 1 * 2-1 | 1/2 |
| 0 * 2-2 | 0 |
| 1 * 2-3 | 1/8 |
In decimal it is rather easy, as we move each position in the fraction to the right, we add a 0 to the denominator. In binary we double the denominator.
As you move along, the denominator doubles so we end up with the following denominator values:| 2-1 | 1/2 |
| 2-2 | 1/4 |
| 2-3 | 1/8 |
| 2-4 | 1/16 |
| 2-5 | 1/32 |
| 2-6 | 1/64 |
and so on.
Converting the binary fraction to a decimal fraction is simply a matter of adding the corresponding values for each bit which is a 1.
In decimal, there are various fractions we may not accurately represent. 1/3 is one of these. We may get very close (eg. 0.3333333333) but we will never exactly represent the value. This is the same with binary fractions however the number of values we may not accurately represent is actually larger. This is not normally an issue becuase we may represent a value to enough binary places that it is close enough for practical purposes. We will come back to this when we look at converting to binary fractions below.
So far we have represented our binary fractions with the use of a binary point. This is fine when we are working with things normally but within a computer this is not feasible as it can only work with 0's and 1's. We get around this by aggreeing where the binary point should be.
So, for instance, if we are working with 8 bit numbers, it may be agreed that the binary point will be placed between the 4th and 5th bits.
01101001 is then assumed to actually represent 0110.1001
A lot of operations when working with binary are simply a matter of remembering and applying a simple set of steps. Converting decimal fractions to binary is no different.
The easiest approach is a method where we repeatedly multiply the fraction by 2 and recording whether the digit to the left of the decimal point is a 0 or 1 (ie, if the result is greater than 1), then discarding the 1 if it is. Once you are done you read the value from top to bottom. Let's look at some examples. This example finishes after 8 bits to the right of the binary point but you may keep going as long as you like. (or until you end up with 0 in your multiplier or a recurring pattern of bits).
0.
Result in Binary :
What we have looked at previously is what is called fixed point binary fractions. These are a convenient way of representing numbers but as soon as the number we want to represent is very large or very small we find that we need a very large number of bits to represent them. If we want to represent the decimal value 128 we require 8 binary digits ( 10000000 ). That's more than twice the number of digits to represent the same value. It only gets worse as we get further from zero.
To get around this we use a method of representing numbers called floating point. Floating point is quite similar to scientific notation as a means of representing numbers. We lose a little bit of accuracy however when dealing with very large or very small values that is generally acceptable. Here I will talk about the IEEE standard for foating point numbers (as it is pretty much the de facto standard which everyone uses).
Some of you may be quite familiar with scientific notation. Some of you may remember that you learnt it a while back but would like a refresher. Let's go over how it works.

In the above 1.23 is what is called the mantissa (or significand) and 6 is what is called the exponent. The mantissa is always adjusted so that only a single (non zero) digit is to the left of the decimal point. The exponent tells us how many places to move the point. In this case we move it 6 places to the right. If we make the exponent negative then we will move it to the left.
If we want to represent 1230000 in scientific notation we do the following:
We may do the same in binary and this forms the foundation of our floating point number.
Here it is not a decimal point we are moving but a binary point and because it moves it is referred to as floating. What we will look at below is what is referred to as the IEEE 754 Standard for representing floating point numbers. The standard specifies the number of bits used for each section (exponent, mantissa and sign) and the order in which they are represented.
There is nothing stopping you representing floating point using your own system however pretty much everyone uses IEEE 754. This includes hardware manufacturers (including CPU's) and means that circuitry spcifically for handling IEEE 754 floating point numbers exists in these devices. By using the standard to represent your numbers your code can make use of this and work a lot quicker. It also means that interoperability is improved as everyone is representing numbers in the same way.
The standard specifies the following formats for floating point numbers:
Single precision, which uses 32 bits and has the following layout:

Double precision, which uses 64 bits and has the following layout.
eg. 0 00011100010 0100001000000000000001110100000110000000000000000000
Double precision has more bits, allowing for much larger and much smaller numbers to be represented. As the mantissa is also larger, the degree of accuracy is also increased (remember that many fractions cannot be accurately represesented in binary). Whilst double precision floating point numbers have these advantages, they also require more processing power. With increases in CPU processing power and the move to 64 bit computing a lot of programming languages and software just default to double precision.
We will look at how single precision floating point numbers work below (just because it's easier). Double precision works exactly the same, just with more bits.
This is the first bit (left most bit) in the floating point number and it is pretty easy. As mentioned above if your number is positive, make this bit a 0. If your number is negative then make it a 1.
The exponent gets a little interesting. Remember that the exponent can be positive (to represent large numbers) or negative (to represent small numbers, ie fractions). Your first impression might be that two's complement would be ideal here but the standard has a slightly different approach. This is done as it allows for easier processing and manipulation of floating point numbers.
With 8 bits and unsigned binary we may represent the numbers 0 through to 255. To allow for negative numbers in floating point we take our exponent and add 127 to it. The range of exponents we may represent becomes 128 to -127. 128 is not allowed however and is kept as a special case to represent certain special numbers as listed further below.
Eg. let's say:
A nice side benefit of this method is that if the left most bit is a 1 then we know that it is a positive exponent and it is a large number being represented and if it is a 0 then we know the exponent is negative and it is a fraction (or small number).
It is easy to get confused here as the sign bit for the floating point number as a whole has 0 for positive and 1 for negative but this is flipped for the exponent due to it using an offset mechanism. It's just something you have to keep in mind when working with floating point numbers.
In scientific notation remember that we move the point so that there is only a single (non zero) digit to the left of it. When we do this with binary that digit must be 1 as there is no other alternative. The creators of the floating point standard used this to their advantage to get a little more data represented in a number.
After converting a binary number to scientific notation, before storing in the mantissa we drop the leading 1. This allows us to store 1 more bit of data in the mantissa.
eg.
If our number to store was 111.00101101 then in scientific notation it would be 1.1100101101 with an exponent of 2 (we moved the binary point 2 places to the left). We drop the leading 1. and only need to store 1100101101.
If our number to store was 0.0001011011 then in scientific notation it would be 1.011011 with an exponent of -4 (we moved the binary point 4 places to the right). We drop the leading 1. and only need to store 011011.
There are a few special cases to consider.
Zero
Zero is represented by making the sign bit either 1 or 0 and all the other bits 0
eg. 1 00000000 00000000000000000000000 or 0 00000000 00000000000000000000000
This would equal a mantissa of 1 with an exponent of -127 which is the smallest number we may represent in floating point. It's not 0 but it is rather close and systems know to interpret it as zero exactly.
Infinity
It is possible to represent both positive and negative infinity. It is simply a matter of switching the sign bit.
To represent infinity we have an exponent of all 1's with a mantissa of all 0's.
eg. 0 11111111 00000000000000000000000 or 1 11111111 00000000000000000000000
Not a Number
This is used to represent that something has happened which resulted in a number which may not be computed. A division by zero or square root of a negative number for example. This is represented by an exponent which is all 1's and a mantissa which is a combination of 1's and 0's (but not all 0's as this would then represent infinity). The sign bit may be either 1 or 0.
eg. 0 11111111 00001000000000100001000 or 1 11111111 11000000000000000000000
The pattern of 1's and 0's is usually used to indicate the nature of the error however this is decided by the programmer as there is not a list of official error codes.
In summary:
| Zero | 0 00000000 00000000000000000000000 |
| Negative Zero | 1 00000000 00000000000000000000000 |
| Infinity | 0 11111111 00000000000000000000000 |
| Negative Infinity | 1 11111111 00000000000000000000000 |
| Not a Number (NaN) | 0 11111111 00001000000000100001000 |
Converting a number to floating point involves the following steps:
Let's work through a few examples to see this in action.
Result in Binary :
To convert from floating point back to a decimal number just perform the steps in reverse.
So the best way to learn this stuff is to practice it and now we'll get you to do just that.
For the first two activities fractions have been rounded to 8 bits. Your numbers may be slightly different to the results shown due to rounding of the result. This is fine.
Education is the kindling of a flame,
not the filling of a vessel.
- Socrates
































